"모든 것의 시작을 찾으면 많은 것을 이해하게 될 것입니다" (Kozma Prutkov).
제 이름은 Ruslan이고 Badoo와 Bumble의 릴리스 엔지니어입니다. 나는 최근에 모바일 프로젝트에서 자동 복구 메커니즘을 최적화해야 할 필요성에 직면했습니다. 문제가 흥미로워서 그 해결책을 여러분과 공유하기로 결정했습니다. 이 기사에서는 이전에 Git 분기의 자동 병합을 구현한 방법과 자동 병합의 처리량을 높이고 프로세스 안정성을 동일한 높은 수준으로 유지한 방법에 대해 설명합니다.
당신의 자동 수리
많은 프로그래머가 매일 git merge를 실행하고 충돌을 해결하고 작업을 테스트합니다. 누군가가 빌드를 자동화하여 별도의 서버에서 자동으로 실행되도록 합니다. 그러나 병합할 분기를 결정하는 것은 여전히 사람의 몫입니다. 누군가는 더 나아가 변경 사항의 자동 병합을 추가하여 지속적인 통합 시스템(지속적 통합 또는 CI)을 얻습니다.
예를 들어, GitHub는 저장소에 대한 쓰기 권한이 있는 사용자가 "자동 병합 허용" 확인란을 선택할 수 있는 반 수동 모드를 제공합니다 . 설정에서 지정한 조건이 충족되면 해당 브랜치는 대상 브랜치에 연결됩니다. Bitbucket은 더 높은 수준의 자동화를 지원 하는 동시에 분기 모델, 분기 이름 및 병합 수에 상당한 제한 을 가합니다.
이러한 종류의 자동화는 소규모 프로젝트에 충분할 수 있습니다. 그러나 개발자와 브랜치가 증가함에 따라 서비스에 의해 부과되는 제한 사항이 CI의 성능에 상당한 영향을 미칠 수 있습니다. 예를 들어, 일관된 병합 전략 덕분에 메인 브랜치가 항상 안정적인 상태를 유지하는 병합 시스템이 있었습니다. 병합을 위한 전제 조건은 개발자 분기에서 모든 업스트림 커밋이 있는 성공적인 빌드였습니다. 이 전략은 안정적으로 작동하지만 빌드 시간 제한이 있습니다. 그리고 이 한도는 충분하지 않았습니다. A를 30 분 처리의 빌드 시간이 하루에 100 병합 이틀 이상 걸릴 것... 이러한 제한을 없애고 병합 전략 및 분기 모델을 최대한 자유롭게 선택하기 위해 자체 자동 병합을 만들었습니다.
그래서 우리는 각 팀의 요구에 적응하는 자체 자동차 수리를 가지고 있습니다. Android 및 iOS 팀이 사용하는 보다 흥미로운 구성표 중 하나의 구현을 살펴보겠습니다.
자귀
기본. 이것이 내가 Git 저장소 의 마스터 브랜치에 연결하는 방법 입니다. 짧고 안전합니다. =)
집회. 이것은 Git 브랜치 및 Jira 추적기의 티켓과 연결된 TeamCity의 빌드를 의미합니다. 최소한 정적 분석, 컴파일 및 테스트를 수행합니다. "To Merge" 티켓 상태와 함께 최신 분기 개정판에 대한 성공적인 빌드는 자동 병합을 위한 전제 조건 중 하나입니다.
분기 모델의 예
모바일 프로젝트에서 다양한 분기 모델을 시도한 결과 다음과 같은 단순화된 버전이 나왔습니다.
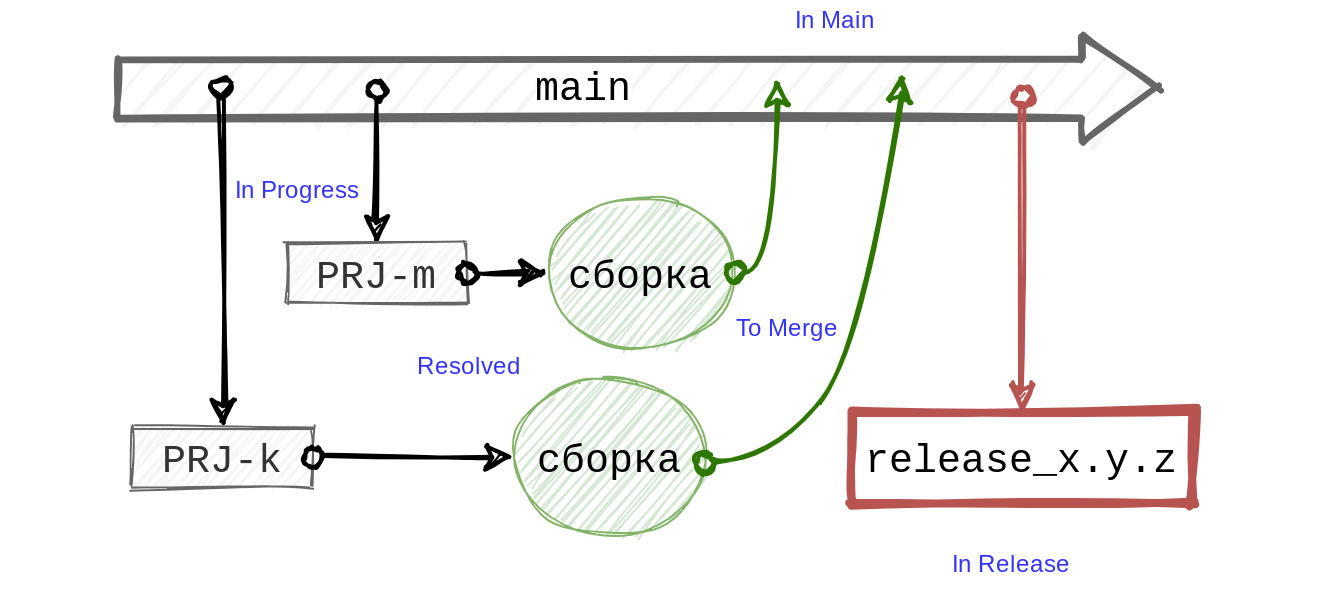
기본 분기를 기반으로 개발자는 추적기의 티켓 ID를 포함하는 이름으로 분기를 만듭니다(예: PRJ-k ) . 티켓에 대한 작업이 완료되면 개발자는 티켓을 "해결됨" 상태로 전환 합니다. 추적기에 내장된 후크를 사용하여 티켓 분기용 빌드를 시작합니다. 특정 순간에 변경 사항이 검토되고 다른 수준의 자동 테스트에 의해 필요한 확인이 완료되면 티켓이 "To Merge" 상태를 수신 하고 자동으로 선택되어 main 으로 전송됩니다 .
일주일에 한 번,에 따라 주, 우리는 릴리스 지점 작성, release_x.y.z,필요한 경우 발사 최종은, 그것을 기반으로 수정 오류, 마지막으로 앱 스토어 또는 구글 플레이에서 릴리스 빌드 결과를 게시 할 수 있습니다. 모든 분기 단계는 Jira 티켓의 상태 및 추가 필드에 반영됩니다 . REST API 클라이언트 는 Jira와 통신하는 데 도움이 됩니다 .
이러한 간단한 모델을 통해 신뢰할 수 있는 자동차 수리를 구축할 수 있을 뿐만 아니라 프로세스의 모든 참가자에게 편리한 것으로 판명되었습니다. 그러나 자동 복구 자체의 구현은 우리가 고성능을 달성하고 충돌, 티켓 다시 열기 및 불필요한 재구축과 같은 부작용의 수를 최소화하기 전에 여러 번 변경되었습니다.
첫 번째 버전: 욕심쟁이 전략
처음에는 단순하고 명백한 것에서 출발했습니다. 우리는 "To Merge" 상태에 있는 모든 티켓을 가져 와서 성공적인 빌드 가 있는 티켓을 선택하여 한 번에 하나씩 메인 팀으로 보냈습니다 git merge.
참고: 첫 번째 버전에 대한 설명을 약간 단순화했습니다. 실제로 는 위에서 설명한 모든 문제가 발생한 메인 브랜치와 개발 브랜치 사이에 dev 브랜치 가 있었습니다. main 을 dev 와 병합하기 전에 24시간 동안 dev 를 기반으로 자동으로 생성된 특수 "통합" 분기를 사용하여 어셈블리를 안정화하려고 했습니다 .
우리는 REST API getAllBuilds 메소드를 사용하여 TeamCity에서 실제 성공적인 빌드가 있는지 대략 다음과 같이 확인했습니다(의사 코드).
haveFailed = False # Есть ли неудачные сборки haveActive = False # Есть ли активные сборки # Получаем сборки типа buildType для коммита commit ветки branch builds = teamCity.getAllBuilds(buildType, branch, commit) # Проверяем каждую сборку for build in builds: # Проверяем каждую ревизию в сборке for revision in build.revisions: if revision.branch is branch and revision.commit is commit: # Сборка актуальна if build.isSuccessful: # Сборка актуальна и успешна return True else if build.isRunning or build.isQueued haveActive = True else if build.isFailed: haveFailed = True if haveFailed: # Исключаем тикет из очереди, переоткрывая его ticket = Jira.getTicket(branch.ticketKey) ticket.reopen("Build Failed") return False if not haveActiveBuilds: # Нет ни активных, ни упавших, ни удачных сборок. Запускаем новую TriggerBuild(buildType, branch)
개정판 은 TeamCity가 빌드하는 커밋입니다. TeamCity 웹 인터페이스에서 빌드 페이지의 변경 탭에 16진수 시퀀스로 표시됩니다. 개정판 덕분에 티켓 분기를 다시 빌드해야 하는지 또는 티켓을 병합할 준비가 되었는지 쉽게 결정할 수 있습니다.
것이 중요 개정 지정 (자주도 필요) 할 수 에서 큐에 새 어셈블리를 추가 요청 매개 변수에서 lastChanges빌드를 시작할 때 다른 인 TeamCity는 오래 가지 버전을 선택할 수 있기 때문에. 아래 도시되는 바와 같이, 그 것이다 필요 하도록 수정을 지정 , 예를 들어 인 TeamCity의 논리 밖에 특정 커밋 (우리의 경우)의 어셈블리에 대한 검색에 기반하는 경우.
티켓을 준비 상태(이 예에서는 "해결됨")로 전송한 후 해당 분기는 일반적으로 변경되지 않으므로 티켓과 관련된 어셈블리가 가장 자주 관련성을 유지합니다. 또한 티켓이 "병합하려면" 상태라는 바로 그 사실은 빌드가 충돌하지 않을 가능성이 높다는 것을 나타냅니다. 결국 어셈블리가 충돌하면 즉시 티켓을 다시 엽니다.
언뜻보기에 추가 조치가 분명해 보입니다. 현재 어셈블리로 모든 기성품 티켓을 가져 와서 주 를 하나씩 연결하십시오 . 자동 병합의 첫 번째 버전에서는 그렇게 했습니다.
모든 것이 빠르게 작동했지만 주의가 필요했습니다. 때때로 여러 티켓의 변경 사항이 서로 충돌하는 상황이 있었습니다. 상당히 광범위한 현상인 합병 중 갈등은 처음에는 누구에게도 특별한 질문을 제기하지 않았습니다. 릴리스 시 근무 중인 개발자가 허용했습니다. 그러나 개발자, 작업 및 그에 따른 분기의 수가 증가함에 따라 릴리스를 순서대로 배치하는 데 점점 더 많은 노력이 필요했습니다. 갈등 해결의 지연은 새로운 도전에 영향을 미치기 시작했습니다. 나는 당신이 이 사슬을 계속해서는 안 된다고 생각합니다. 아마도 당신은 이미 제 말을 이해하고 있을 것입니다. 충돌과 관련하여 무언가를 수행해야 했으며 릴리스에 포함되지 않도록 해야 했습니다.
충돌 병합
다른 브랜치에서 같은 코드 줄을 변경하고 main 에서 병합하려고 하면 Git은 병합 충돌 을 해결하도록 요청합니다 . 두 가지 옵션 중 하나를 선택하고 변경 사항을 커밋해야 합니다.
이것은 거의 모든 VCS 사용자에게 친숙할 것입니다. 모든 VCS 사용자와 마찬가지로 CI 프로세스는 충돌을 해결해야 합니다. 사실, 이것은 코드 기반에 대한 거의 완전한 오해의 조건에서 약간 맹목적으로 수행되어야 합니다.
명령 경우 git merge오류 및과 끝 git ls-files --unmerged충돌 핸들러가 지정된 목록에있는 모든 파일에 대해 , 각각의 해당 파일에 대해 우리가 충돌 마커에 의한 내용을 분석 <<<<<<<, =======하고 >>>>>>>.갈등 만 응용 프로그램 버전의 변화에 의해 발생하는 경우, 예를 들어, 충돌의 로컬 부분과 원격 부분 사이에서 최신 버전을 선택하십시오.
병합 충돌은 CI에서 가장 간단한 충돌 유형 중 하나입니다. main 과 충돌 하는 경우 CI는 개발자에게 문제를 알리고 새 커밋이 나타날 때까지 다음 자동 복구 주기에서 분기를 제외해야 합니다.
해결책은 다음과 같습니다. 병합에 대한 전제 조건 중 하나 이상을 위반합니다 . 스레드가 추적기 티켓과 연결되어 있으므로 상태를 변경하여 티켓을 다시 열 수 있습니다. 따라서 우리는 자동 서비스에서 티켓을 동시에 제외하고 개발자에게 이에 대해 알립니다(결국 그는 티켓의 변경 사항에 가입했습니다). 만일을 대비하여 메신저로도 메시지를 보냅니다.
논리적 충돌
한 쌍의 분기 어셈블리가 개별적으로 성공했음에도 불구하고 메인 브랜치 와 병합한 후 메인 분기 의 어셈블리가 충돌할 수 있습니까? 연습은 그것이 가능하다는 것을 보여줍니다. 예를 들어, 두 분기 각각 에 있는 와 b 의 합이 5를 초과 하지 않으면 이 분기 에서 a 와 b 의 누적 변화 가 더 큰 합으로 이어지지 않는다는 보장 이 없습니다.
Bash 스크립트의 예를 사용하여 이것을 재현해 보겠습니다 test.sh.
#!/bin/bash get_a() { printf '%d\n' 1 } get_b() { printf '%d\n' 2 } check_limit() { local -i value="$1" local -i limit="$2" if (( value > limit )); then printf >&2 '%d > %d%s\n' "$value" "$limit" exit 1 fi } limit=5 a=$(get_a) b=$(get_b) sum=$(( a + b )) check_limit "$a" "$limit" check_limit "$b" "$limit" check_limit "$sum" "$limit" printf 'OK\n'
의 그것을 커밋 및 지점의 몇 가지를 만들어 보자 : 와 B를 . 함수의 첫 번째 분기가 3 을 반환 하고 두 번째 분기 가 4를 반환 한다고 가정합니다 .
get_a()get_b()
diff --git a/test.sh b/test.sh index f118d07..39d3b53 100644 --- a/test.sh +++ b/test.sh @@ -1,7 +1,7 @@ #!/bin/bash get_a() { - printf '%d\n' 1 + printf '%d\n' 3 } get_b() { git diff main b diff --git a/test.sh b/test.sh index f118d07..0bd80bb 100644 --- a/test.sh +++ b/test.sh @@ -5,7 +5,7 @@ get_a() { } get_b() { - printf '%d\n' 2 + printf '%d\n' 4 } check_limit() {
두 경우 모두 금액이 5를 초과하지 않으며 테스트가 성공적입니다.
git checkout a && bash test.sh Switched to branch 'a' OK git checkout b && bash test.sh Switched to branch 'b' OK
그러나 main 을 분기와 병합한 후 명백한 충돌이 없음에도 불구하고 테스트 통과가 중지됩니다.
git merge a b Fast-forwarding to: a Trying simple merge with b Simple merge did not work, trying automatic merge. Auto-merging test.sh Merge made by the 'octopus' strategy. test.sh | 4 ++-- 1 file changed, 2 insertions(+), 2 deletions(-) bash test.sh 7 > 5
"대신에 할당 get_a()이 get_b()사용 된다면 더 쉬울 것입니다 . a=1; b=2" -주의 깊은 독자는 알아 차리고 옳을 것입니다. 예, 더 쉬울 것입니다. 그러나 이것이 아마도 내장된 Git 자동 복구 알고리즘이 충돌 상황을 성공적으로 감지하는 이유일 것입니다(이로 인해 논리적 충돌 문제를 시연할 수 없음 ).
git merge a Updating 4d4f90e..8b55df0 Fast-forward test.sh | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) git merge b Auto-merging test.sh CONFLICT (content): Merge conflict in test.sh Recorded preimage for 'test.sh' Automatic merge failed; fix conflicts and then commit the result.
물론 실제로는 갈등이 덜 분명합니다. 예를 들어, 최신 버전이 이전 버전과의 호환성을 지원하지 않더라도 다른 분기는 종속성 라이브러리의 다른 버전의 API에 의존할 수 있습니다. 코드 기반에 대한 깊은 지식 없이는 거의 불가능합니다(읽기: 프로젝트 개발자 없이). 그러나 CI는 바로 이러한 문제를 해결하는 데 필요한 것입니다.
물론, 우리는 갈등 해결에서 벗어나지 않을 것입니다. 누군가는 수정을 해야 합니다. 그러나 문제를 빨리 찾을수록 문제 해결에 참여하는 사람이 줄어듭니다. 이상적으로는 충돌하는 분기 중 하나의 개발자만 의아해할 필요가 있습니다. 그러한 분기가 두 개 있으면 그 중 하나가 main 에 연결될 수 있습니다 .
예방 조치
따라서 가장 중요한 것은 논리적 충돌이 main 으로 들어가는 것을 방지하는 것입니다 . 그렇지 않으면 오류의 원인을 찾고 문제를 해결해야 하거나 해결할 수 있는 프로그래머를 찾기 위해 길고 고통스러운 검색이 필요합니다. 더욱이 이것은 첫째, 릴리스 지연을 방지하고 둘째, 이미 식별된 충돌을 기반으로 하는 새 분기의 논리적 충돌을 피하기 위해 가능한 한 빠르고 효율적으로 수행되어야 합니다. 이러한 충돌은 종종 애플리케이션의 많은 부분을 작동하지 못하게 하거나 실행을 차단하기도 합니다.
main에 대한 결합된 기여로 인해 릴리스 빌드가 저하되지 않도록 분기를 동기화해야 합니다 . 병합할 준비가 된 모든 분기는 어떤 방식으로든 병합되어야 하며 병합 결과를 기반으로 테스트를 실행해야 합니다. 많은 솔루션이 있습니다. 우리의 경로가 무엇인지 봅시다.
두 번째 버전: 순차 전략
기존 티켓 자동 수리 준비 조건이 충분하지 않다는 것이 분명해졌습니다. 그것은 지점들 사이에 일종의 동기화 기능, 일종의 순서가 필요했습니다.
Git은 이론적으로 동기화 도구일 뿐입니다. 그러나 우리 스스로는 판단 가지 입력하는 순서 주 와 반대로, 주요 지점에 있습니다. main 에서 문제를 일으키는 분기를 정확히 확인하려면 한 번에 하나씩 푸시해 볼 수 있습니다. 그런 다음 대기열에 넣고 티켓이 " 선착순" 스타일로 " 병합" 상태가 된 시간을 기준으로 주문을 구성할 수 있습니다 .
우리는 주문을 결정했습니다. 가지를 더 연결하는 방법은 무엇입니까? 대기열 의 첫 번째 티켓 을 main 에 병합한다고 가정해 보겠습니다 . 때문에 메인이 변경되었습니다, 그것은 큐에있는 티켓의 나머지 부분과 충돌 할 수 있습니다. 따라서 다음 티켓을 병합하기 전에 업데이트된 메인 이 여전히 호환 되는지 확인해야 합니다. 이렇게 하려면 main 을 티켓 으로 병합하는 것으로 충분합니다 . 그러나 main이 분기에 연결된 후 어셈블리의 상태와 다르기 때문에 어셈블리를 다시 시작해야 합니다. 순서를 유지하려면 대기열의 다른 모든 티켓이 빌드가 완료되고 업스트림 티켓이 처리될 때까지 기다려야 합니다. 이러한 종류의 추론은 우리를 일관된 자동 수리 전략으로 이끌었습니다.
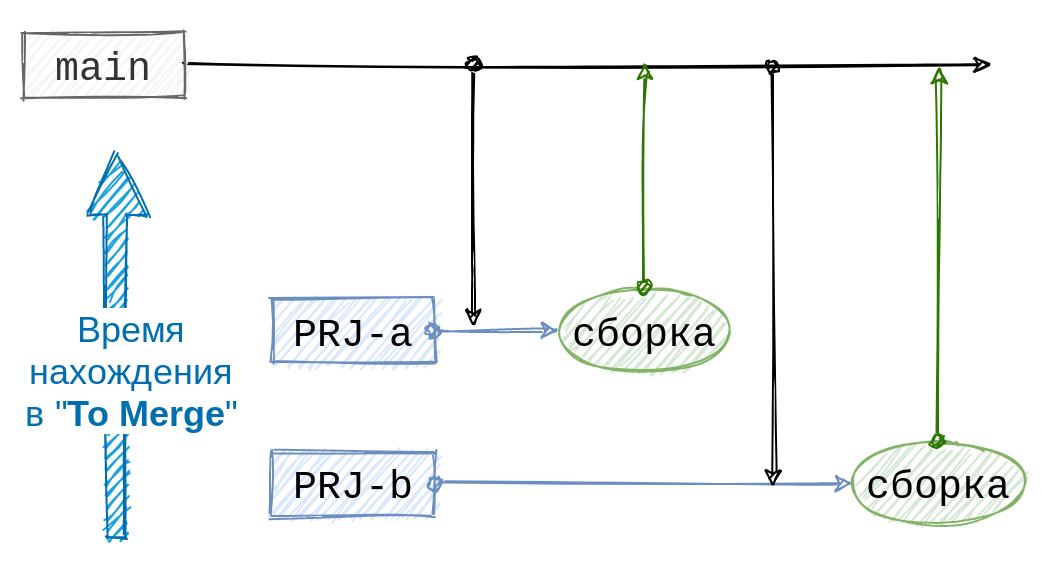
이 계획은 안정적이고 예측 가능하게 작동합니다. main 과 의 의무적인 동기화 및 후속 재구축으로 인해 분기 간의 충돌이 main 에 도달하기 전에 즉시 감지할 수 있습니다 . 이전에는 대부분의 분기가 이 충돌과 관련이 없는 릴리스를 병합한 후 충돌을 해결해야 했습니다. 또한 알고리즘의 예측 가능성을 통해 웹 인터페이스에 티켓 대기열을 표시할 수 있으므로 분기가 main 에 도달하는 속도를 대략적으로 추정할 수 있습니다 .
그러나 이 방식에는 중요한 단점이 있습니다. 자동 병합 처리량은 조립 시간에 선형적으로 의존합니다. 평균 iOS 애플리케이션 빌드 시간이 25분이므로 하루에 최대 57개의 티켓을 전달할 수 있습니다. 안드로이드 애플리케이션의 경우 약 45분 정도 소요되며, 이는 자동 서비스를 하루 32개 티켓으로 제한하는데, 이는 우리 회사의 안드로이드 개발자 수보다 훨씬 적은 수치다.
실제로 " To Merge " 상태의 티켓 대기 시간은 평균 2시간 40분이었고 "버스트"는 최대 10시간에 이릅니다! 최적화의 필요성이 분명해졌습니다. 일관된 전략의 안정성을 유지하면서 합병의 속도를 높이는 것이 필요했습니다.
Final Cut: 일관되고 욕심 많은 전략의 조합
IOS 팀 개발자 Damir Davletov는 일관된 전략의 장점을 유지하면서 탐욕적인 전략의 아이디어로 돌아갈 것을 제안했습니다.
탐욕스러운 전략의 아이디어를 기억합시다. 기성품 티켓의 모든 분기를 main 에 병합했습니다 . 주요 문제는 지점 간의 동기화 부족이었습니다. 해결하시면 빠르고 안정적인 자동수리를 해드리겠습니다!
당신은 "모든 티켓의 총 기여도를 평가해야하기 때문에 병합" 상태 에 대한 주요 이유는 모든 지점을 병합 할 몇 가지 중간에 "메인 후보"(MC) 지점 과의 빌드를 실행? 빌드가 성공하면 MC 를 main 에 안전하게 병합할 수 있습니다 . 그렇지 않으면 MC 에서 일부 티켓을 제외 하고 빌드를 다시 시작해야 합니다.
제외할 티켓을 어떻게 알 수 있나요? n 장의 티켓 이 있다고 합시다 . 실제로 빌드 충돌의 가장 일반적인 이유는 하나의 티켓입니다. 그것이 어디에 있는지 우리는 모릅니다 . 1 에서 n 까지의 모든 위치 는 동일합니다. 따라서 문제 티켓을 찾기 위해 n 을 반으로 나눕니다 .
대기열에 있는 티켓은 «To Merge» 상태에 도달하는 시간에 따라 결정 되므로 나머지 절반을 가져오는 것이 좋습니다. 여기에는 약 lshim 대기 시간 이 b인 티켓이 있습니다 .
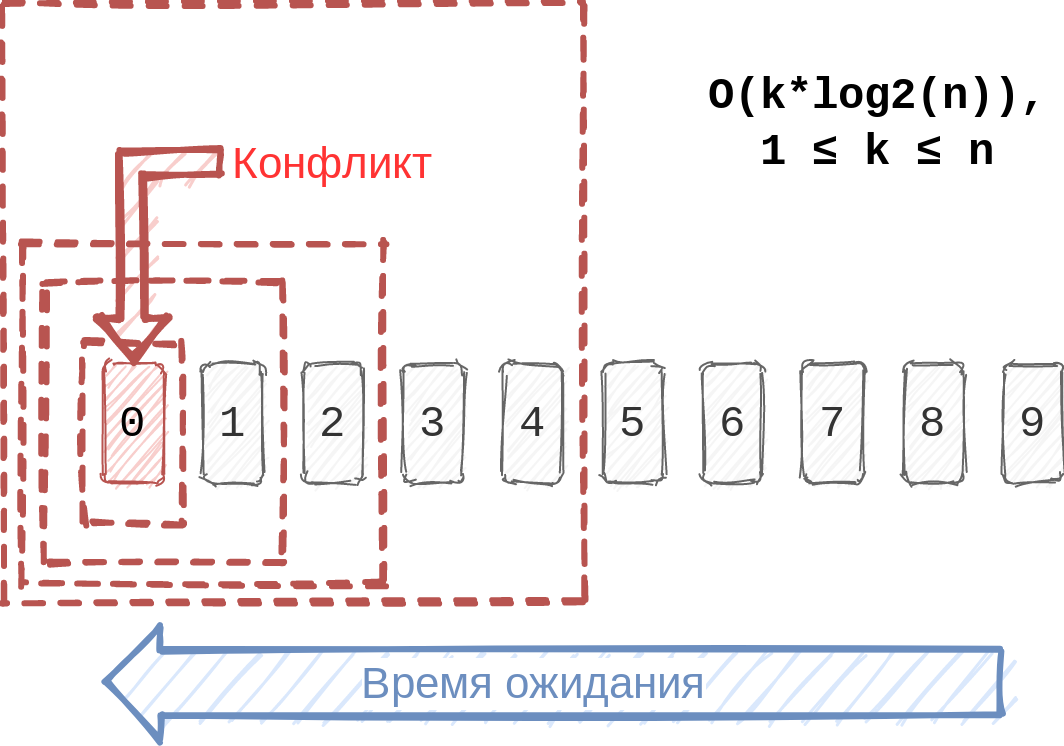
이 알고리즘에 따르면 k개의 문제가 있는 티켓 에 대해 최악의 경우O(k*log2(n)) 모든 문제가 있는 티켓을 처리하고 나머지에서 성공적인 빌드를 얻기 전에 빌드 를 수행해야 합니다.
유리한 결과가 나올 가능성이 높습니다. MC 브랜치의 빌드 가 떨어지는 동안 순차 알고리즘을 사용하여 작업을 계속할 수 있습니다!
그래서 우리는 두 가지 자동 병합 모델이 있습니다: 순차( "순차 병합" 또는 SM 이라고 합시다) 및 탐욕( "탐욕 병합" 또는 GM 이라고 합시다 ). 둘 다의 이점을 얻으려면 병렬로 작동하도록 설정해야 합니다. 그리고 병렬 프로세스에는 동기화가 필요하며 프로세스 간 통신 또는 비차단 동기화 또는 이 둘의 조합을 통해 달성할 수 있습니다 . 어쨌든 다른 방법은 나에게 알려지지 않았습니다.
이러한 종류의 프로세스 자체는 스크립트 명령 대기열의 형태로 구현됩니다. 이 명령은 할 수 있습니다 한 번 하고 주기적으로 실행 . 자동 측정이 끝나지 않고 대기열 컨트롤러가 재실행을 더 잘 관리하므로 두 번째 유형을 선택합니다.
가능한 모든 경합 상태 를 방지하는 것 입니다. 그 중 많은 것이 있지만 본질을 이해하기 위해 가장 중요한 몇 가지를 알려 드리겠습니다.
- SM-SM 및 GM-GM: 같은 유형의 팀 간.
- SM-GM: 동일한 저장소 내의 SM과 GM 사이.
첫 번째 문제는 명령 이름과 저장소 이름을 포함 하는 토큰 뮤텍스 를 사용하여 쉽게 해결할 수 있습니다 . 예 lock_${command}_${repository}.
두 번째 경우의 복잡성이 무엇인지 설명하겠습니다. SM과 GM이 일관되지 않게 행동하면 SM 이 대기열의 첫 번째 티켓과 main 을 연결할 수 있지만 GM은 이 티켓을 알아채지 못합니다 . 즉, 첫 번째 티켓을 고려하지 않고 다른 모든 티켓을 수집합니다. 예를 들어 SM이 티켓을 In Master 상태 로 이동하고 GM이 항상 To Merge 상태로 티켓을 선택하는 경우 GM은 SM에 의해 연결된 티켓을 처리하지 않을 수 있습니다. 또한 첫 번째 티켓이 다른 티켓 중 적어도 하나와 충돌할 수 있습니다.
논리적 충돌을 피하기 위해 GM은 예외 없이 대기열의 모든 티켓을 처리해야 합니다 . 같은 이유로 SM과 함께 GM 알고리즘 은 반드시 SM과 같은 대기열의 티켓 순서를 따라야 합니다 . GM에서 빌드가 실패한 경우 대기열의 어느 절반이 선택되는지 결정하는 것은 이 순서이기 때문입니다. 이러한 조건이 충족되면 SM에서 처리한 티켓은 항상 GM 어셈블리에 포함되어 필요한 동기화 수준을 제공합니다.
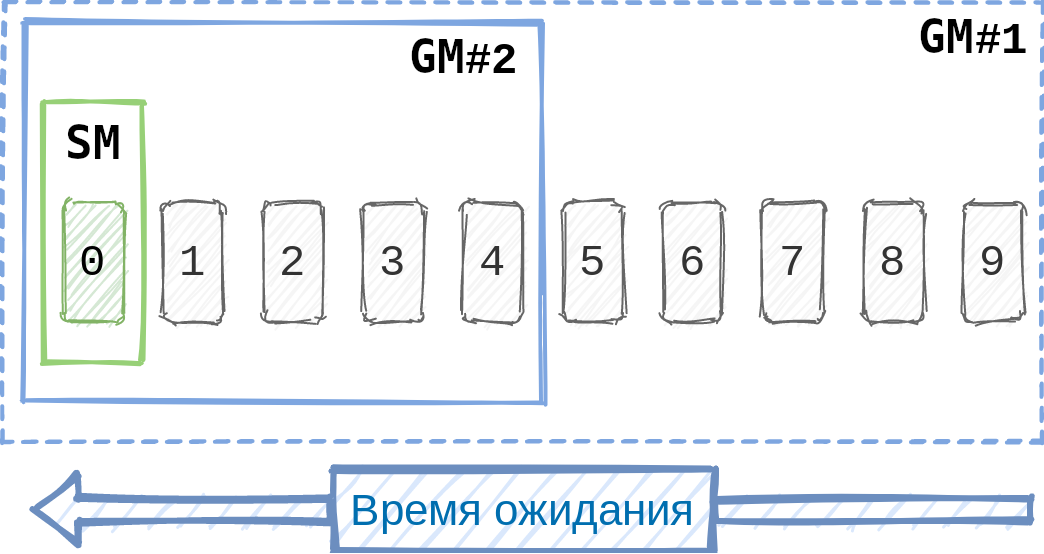
따라서 우리는 일종의 비 차단 동기화를 얻었습니다.
TeamCity에 대해 조금
GM을 구현하는 과정에서 우리는 기사에 과부하가 걸리고 싶지 않은 많은 뉘앙스를 처리해야했습니다. 그러나 그들 중 하나는 주목할 가치가 있습니다. 개발하는 동안 GM 팀 루핑에 문제가 발생했습니다. 프로세스는 지속적으로 MC 브랜치 를 재구축하고 TeamCity에서 새 어셈블리를 생성하는 것이었습니다 . 문제는 TeamCity가 몇 초 전에 GM 프로세스에 의해 생성된 MC 분기가 있는 저장소 업데이트를 다운로드하지 못했다는 것입니다 . 참고로 TeamCity에서 리포지토리 업데이트 간격은 약 30초입니다.
핫픽스로 플로팅 어셈블리 태그를 도입했습니다. 즉 automerge_ios_repo_git, 와 비슷한 이름으로 TeamCity에 태그를 생성하고 어떤 어셈블리가 현재 어떤 상태인지 파악하기 위해 어셈블리에서 어셈블리로 이동했습니다. 등등입니다. 하지만 이 접근 방식의 불완전함을 깨닫고 TeamCity에 MC 브랜치의 새로운 상태를 알리는 방법과 어셈블리에 개정판을 첨부하는 방법을 찾기 시작했습니다.
누군가는 해결책을 뻔하다고 생각할 것이지만 나는 즉시 그것을 찾지 못했습니다. addBuildToQueuelastChanges 메소드 매개변수를 사용 하여 큐에 추가될 때 어셈블리에 개정을 첨부할 수 있습니다 .
<lastChanges> <change locator="version:{{revision}},buildType:(id:{{build_type}})"/> </lastChanges>
이 예에서 {{revision}}는 16진 커밋 시퀀스 및 {{build_type}}빌드 구성 ID로 바꿉니다 . 그러나 새 커밋에 대한 정보가 없는 TeamCity가 요청을 거부할 수 있기 때문에 이것으로 충분하지 않습니다.
TeamCity에 새로 온 것을 커밋하려면 구성 설정의 루트인 VCS에 표시된 시간 동안 기다리거나 requestPendingChangesCheck 메서드를 사용하여 TeamCity에 저장소 변경 사항( «Pending Changes»)을 확인하도록 요청해야 합니다 . 그런 다음 TeamCity가 커밋이 포함된 변경 사항을 다운로드할 때까지 기다립니다. 이러한 종류의 검사는 적어도 커밋 자체가 로케이터 매개변수로 changeLocator 에서 전달되어야 하는 getChange 메소드를 통해 수행됩니다 . 그건 그렇고, 이 작성(및 코드) 당시에 는 공식 문서 의 페이지 에 매개변수 에 대한 설명 이 없었습니다. 아마도 그것이 내가 그 존재에 대해 즉시 알지 못하고 40자의 16진수 커밋 해시라는 것을 알게 된 이유일 것입니다. versionChangeLocator version
의사 코드:
teamCity.requestPendingChanges(buildType) attempt = 1 while attempt <= 20: response = teamCity.getChange(commit, buildType) if response.commit == commit: return True # Дождались sleep(10) return False
매우 높은 합병 비율에 대해
탐욕스러운 전략에는 결함이 있는 분기를 찾는 데 오랜 시간이 걸릴 수 있다는 단점이 있습니다. 예를 들어, 20장의 티켓에 대해 6개의 어셈블리를 수행하는 데 약 3시간이 걸릴 수 있습니다. 이 단점을 없앨 수 있을까요?
대기열에 10개의 티켓 이 있다고 가정해 보겠습니다. 그 중 6번째 티켓만 빌드에서 실패로 이어집니다.

탐욕스러운 전략 에 따라 한 번에 10 장의 티켓을 모두 수집하려고 하여 빌드가 떨어집니다. 다음 으로 오류가 있는 티켓이 오른쪽 절반에 남아 있기 때문에 왼쪽 절반( 1 에서 5까지 )을 성공적으로 수집합니다 .

대기열의 왼쪽 절반에서 빌드를 막 시작했다면 시간을 낭비하지 않았을 것입니다. 그리고 문제가 6번째 티켓이 아니라 4 번째 티켓 이라면 전체 대기열 길이의 1/4, 즉 티켓 1 ~ 3 에서 조립을 시작하는 것이 유리할 것 입니다.

이 생각을 계속하면서 모든 티켓 조합의 어셈블리가 병렬로 실행되는 경우에만 실패한 어셈블리에 대한 기대를 완전히 제거할 수 있다는 결론에 도달합니다 .
충돌을 피하기 위해 여기에서 순서를 준수해야 하므로 "다섯 번째 및 첫 번째"와 같은 조합은 허용되지 않습니다. 그런 다음 성공적인 빌드를 가져와서 해당 티켓을 main 에 병합할 수 있습니다 . 동시에 실패한 조립에는 시간이 걸리지 않습니다.
유사한 알고리즘이 "Merge Trains" 라는 GitLab의 프리미엄 기능에서 구현됩니다 . 이 이름을 러시아어로 번역한 것을 찾지 못했기 때문에 "Merge Trains"라고 부를 것입니다. "train"은 주 분기("병합 요청")와의 "병합 요청" 대기열입니다. 이러한 각 요청에 대해 요청 자체 분기의 변경 사항은 이전에 있는 모든 요청(즉, 이전에 "훈련"에 추가된 요청)의 변경 사항과 병합됩니다. 예를 들어 세 가지 병합 요청 A , B 및 C에 대해 GitLab은 다음 어셈블리를 생성합니다.
- A 의 변경 사항이 메인 라인에 병합되었습니다.
- 메인 브랜치에 연결된 A 와 B 의 변경 사항 .
- 에서 변경 A, B, 그리고 C 의 주요 지점에 연결.
어셈블리가 충돌하면 해당 요청이 대기열에서 제거되고 모든 이전 요청의 어셈블리가 다시 시작됩니다(원격 요청 제외).
GitLab은 동시 빌드 수를 20개로 제한합니다. 다른 모든 어셈블리는 기차 외부의 대기 대기열로 이동합니다. 어셈블리가 작업을 완료하자마자 대기 대기열의 다음 어셈블리가 그 자리를 차지합니다.
따라서 모든 유효한 대기열 티켓 조합에서 병렬 빌드를 실행하면 매우 빠른 병합 속도가 가능합니다 . 대기줄을 없애면 최대 속도까지 도달할 수 있습니다.
그러나 인간의 생각에 장벽이 없다면 하드웨어 리소스의 한계가 명확하게 보입니다.
- 각 빌드에는 TeamCity의 자체 에이전트가 필요합니다.
- 우리의 경우 모바일 애플리케이션 어셈블리에는 약 15-100개의 종속성 어셈블리가 있으며 각 종속성 어셈블리 는 에이전트로 구분해야 합니다.
- 자동 수리 모바일 애플리케이션의 어셈블리 주요 인 TeamCity에서 어셈블리의 총 수의 메이크업까지 작은 부분.
모든 찬반 양론을 저울질한 후, 우리는 지금 SM + GM 알고리즘에 대해 이야기하기로 결정했습니다 . 현재 티켓 대기열의 성장률에서 알고리즘은 좋은 결과를 보여줍니다. 미래에 가능한 대역폭 문제가 발견되면 "Merge Trains"로 이동하여 몇 가지 병렬 GM 빌드를 추가할 것입니다 .
- 전체 대기열입니다.
- 대기열의 왼쪽 절반입니다.
- 대기열의 왼쪽 4분의 1입니다.
결국 무슨 일이 일어 났니
결합된 자동 수리 전략을 적용한 결과 다음을 달성했습니다.
- 평균 대기열 크기가 2-3 배 감소합니다 .
- 평균 대기 시간이 4-5 배 감소합니다 .
- 언급된 각 프로젝트에서 하루에 약 50 개의 지점을 병합 합니다.
- 높은 수준의 신뢰성을 유지하면서 자동 측정의 처리량을 증가시킵니다. 즉, 일일 티켓 수에 대한 제한을 실질적으로 제거했습니다 .
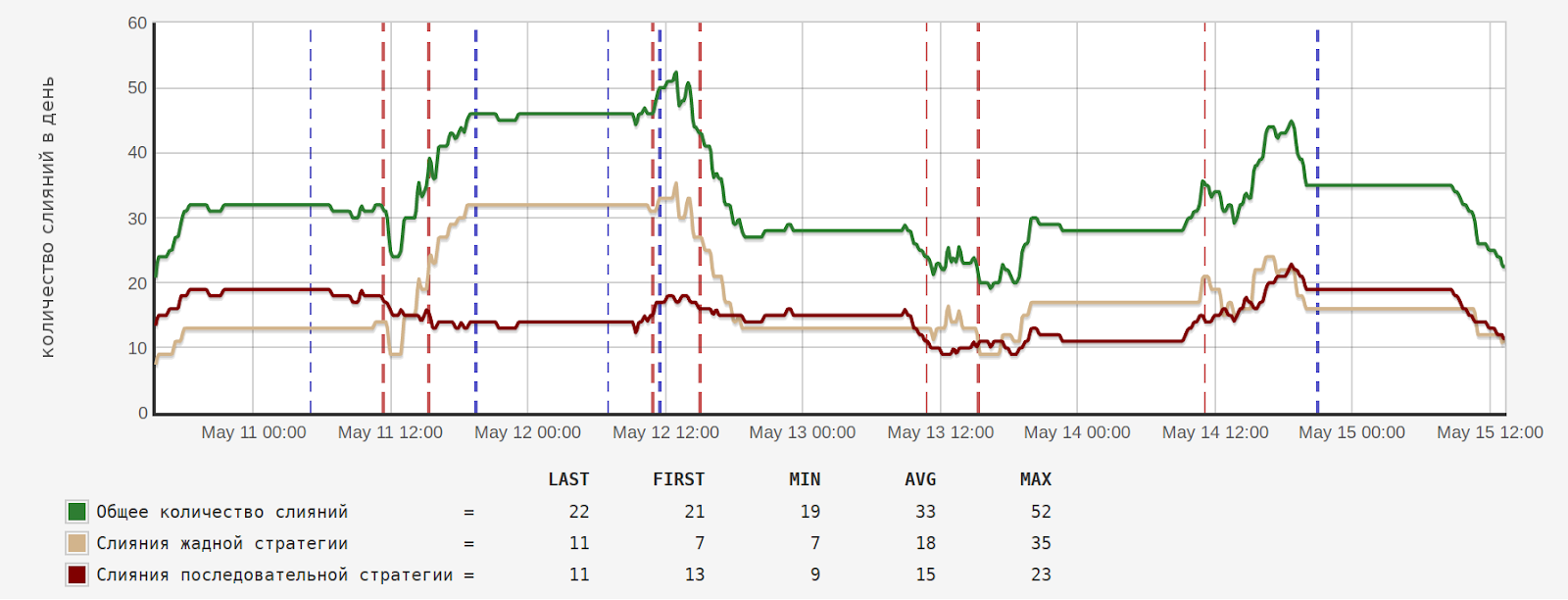
며칠에 걸친 병합 차트의 예:
새 알고리즘 구현 전후의 대기열에 있는 티켓 수:
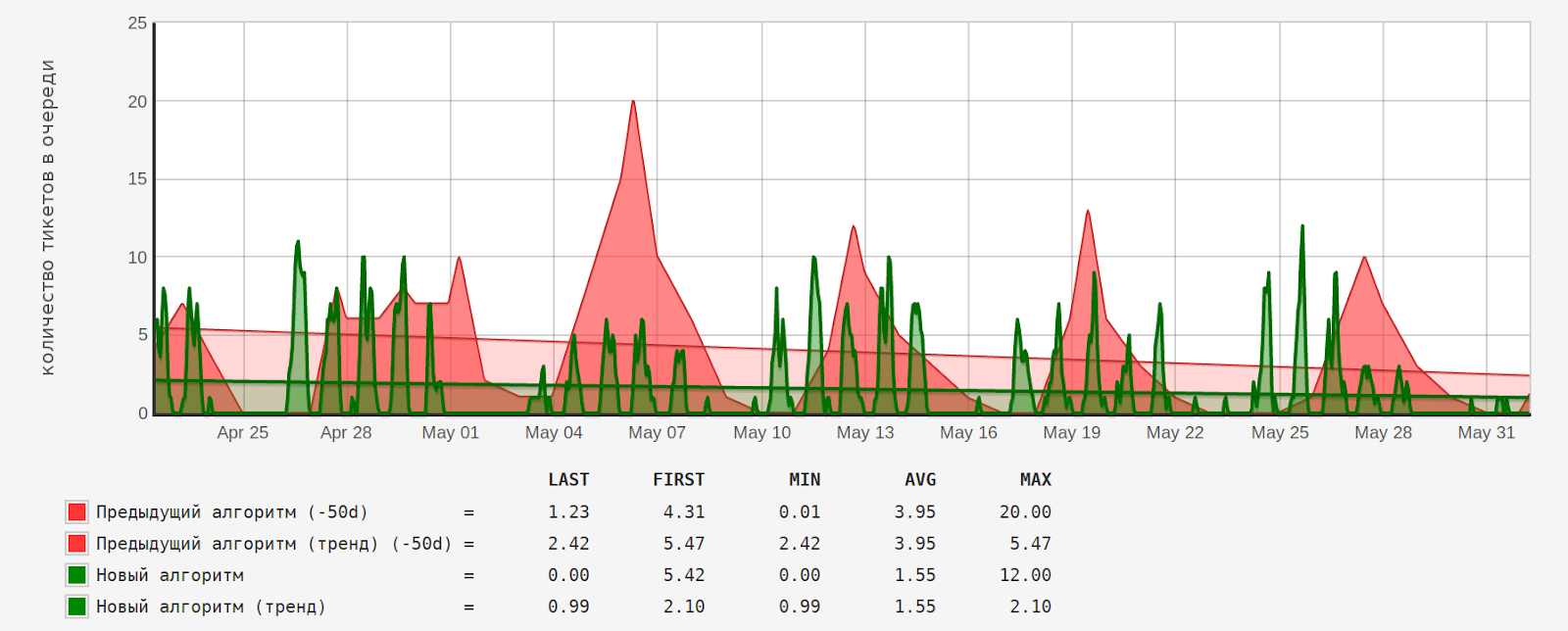
대기열의 평균 티켓 수("AVG")는 2.5배(3.95/1.55) 감소했습니다.
티켓 대기 시간(분):
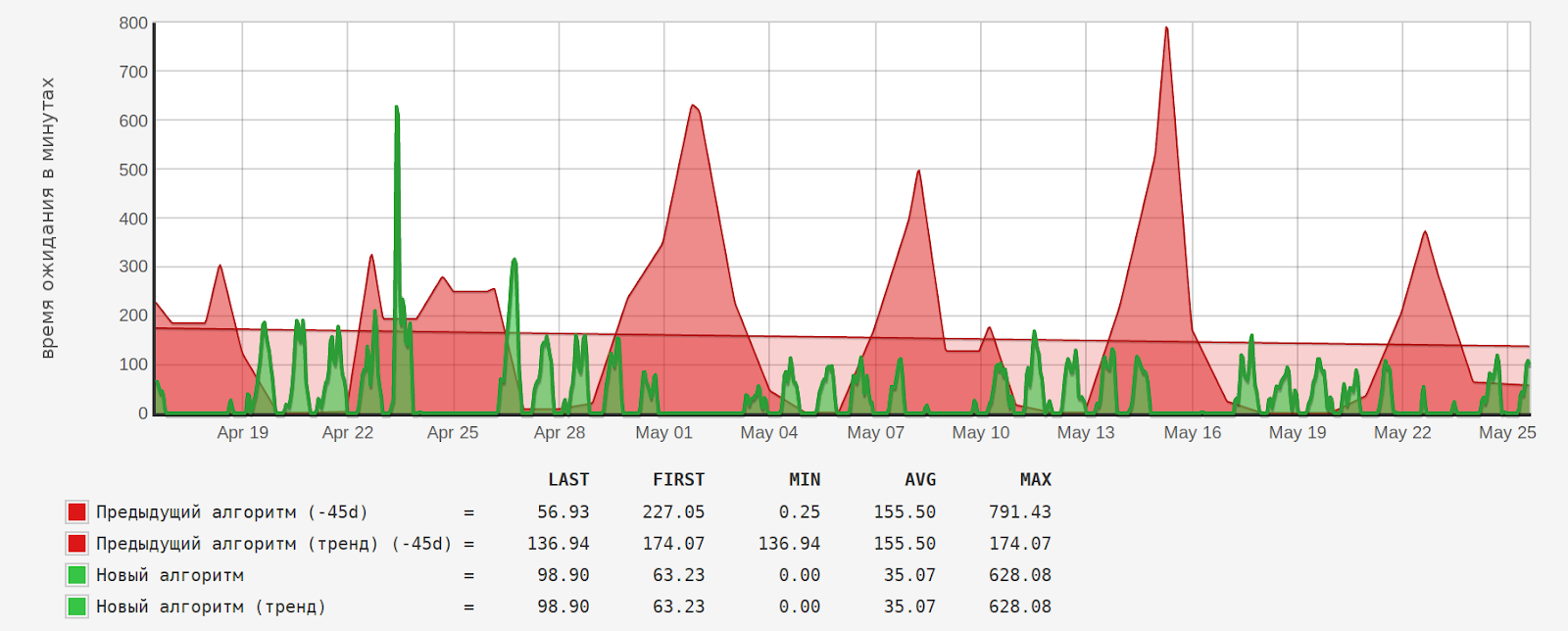
평균 대기 시간("AVG")이 4.4배(155.5/35.07) 감소했습니다.
댓글